Salesforce Data Cloud explained: a guide to building a real-time customer data foundation

Customer data is growing faster than most organizations can manage it. CRM systems, e-commerce platforms, mobile apps, and marketing tools all collect valuable signals, yet those signals rarely connect in real time. As a result, many organizations struggle to build a unified view of the people they serve and turn insights into action.
The customer data platform market is growing fast, with global CDP spending expected to expand sharply in the coming years as companies seek real-time profiles and activation capabilities. At the same time, adoption of Salesforce’s Data Cloud has surged, with customer count jumping more than 140% year over year and organizations connecting trillions of records to power AI, activation, and analytics.
This guide provides a practical Salesforce Data Cloud (Salesforce Data 360) overview, from core architecture and key features to real implementation patterns and common mistakes. It explains how organizations use Data Cloud to move from fragmented data to unified customer profiles, near-real-time segmentation, and cross-cloud activation. The focus is not on theory or marketing promises, but on how Data Cloud works in real projects and how to approach implementation with clear structure and intent.
What is Salesforce Data Cloud (and what it’s not)
Salesforce Data Cloud is a real-time customer data platform built into the Salesforce ecosystem. It brings customer, behavioral, and transactional data from many systems into one continuously updated profile that teams can use for activation, analytics, and AI.
Salesforce has recently rebranded Data Cloud to Data 360. Previously, the platform was positioned as a customer data unification layer, and it has now been redesigned as an operational data foundation that supports real-time decision-making, automation, and AI across Salesforce clouds.
Data Cloud works as an execution layer, where the platform standardizes data flows from CRM, e-commerce platforms, mobile apps, websites, marketing tools, and external systems, connects identities across channels, and keeps profiles current as new events arrive. Those profiles can be used immediately across Salesforce products and connected tools.
What Data Cloud (Salesforce Data 360) does in practice
Data Cloud focuses on four core jobs:
- Unify customer data. Data from different sources is aligned into a common model so profiles follow the same structure, regardless of where the data originated.
- Resolve identity across systems. Known and anonymous records are linked using deterministic and probabilistic rules. Multiple records that refer to the same person are merged into one profile.
- Keep profiles fresh. Updates flow in near real time, allowing segmentation and activation to reflect current behavior instead of outdated snapshots.
- Activate data where work happens. Unified profiles and segments are used in marketing, service, commerce, analytics, and AI workflows without constant data exports.
What Data Cloud (Salesforce Data 360) is not
Clear expectations matter before any implementation starts.
- Data Cloud is not a data lake replacement. Long-term storage, raw analytics, and large-scale historical analysis still belong in data warehouses.
- Data Cloud is not a reporting tool. Dashboards and analysis consume Data Cloud data, but reporting lives in tools such as Tableau or CRM Analytics.
- Data Cloud is not a plug-and-play personalization feature. Identity design, data modeling, governance, and activation strategy require deliberate architectural decisions.
Why organizations use Data Cloud
Organizations adopt Salesforce Data Cloud when existing systems cannot deliver a trusted, real-time view of the customer. Common drivers include:
- Low identity match rates across channels;
- Slow segment refresh and delayed activation;
- Inconsistent customer context between marketing and service;
- Limited ability to support AI and automation with reliable data.
Salesforce Data Cloud use cases we see in large organizations: a real enterprise scenario
Our client is a global B2C retailer operating across multiple digital and offline channels. The company serves millions of customers worldwide through a combination of:
- Salesforce CRM for customer and service data;
- An e-commerce platform handling online transactions;
- A mobile app capturing behavioral and engagement events;
- Paid media platforms for acquisition and retargeting.
Each system evolved on its own. None of them shared customer data in real time, which increased complexity as the company scaled.
Core challenge
Customer identity was fragmented across platforms. One person could exist as multiple CRM records, anonymous digital profiles, and separate marketing IDs. The fragmentation caused several issues:
- High data duplication and inconsistent profiles;
- Low identity match rates across systems;
- Long delays between data updates and activation;
- Low trust in segmentation and reporting.
Marketing teams worked with outdated snapshots instead of live customer context. Real-time personalization was not possible.
Our approach with Salesforce Data Cloud
Our team implemented Salesforce Data Cloud as a central customer data layer. Rather than adding more custom integrations, we connected CRM, commerce, mobile, and marketing data into one continuously updated profile.
Key steps included:
- Unifying customer, behavioral, and transactional data;
- Resolving duplicates and linking identities across channels;
- Making customer behavior available in near real time;
- Enabling activation across marketing, service, analytics, and AI use cases.
We helped the client to shift from static segmentation to behavior-based engagement powered by live data.
AI-driven use cases
With clean and connected data in place, AI models ran on top of trusted customer profiles. Teams can easily:
- Identify high-intent customers earlier;
- Predict churn risk based on real behavior;
- Prioritize audiences with higher conversion potential;
- Move decisions from reactive to proactive.
Salesforce Data 360 implementation results
The impact appeared within weeks:
- Identity match rate increased from 20% to 85%;
- Segment refresh time dropped from 72 hours to under 20 minutes;
- Campaign click-through rates increased by 25%;
- Integration and maintenance costs decreased by 30%.
Salesforce Data Cloud features and architecture
Salesforce Data Cloud, now branded as Data 360, is built as an operational data layer. Its architecture is designed to move data from ingestion to activation without long delays or manual handoffs. The goal is simple: keep customer data usable, current, and ready for action across Salesforce and connected systems.
Below is a practical view of the architecture and the core Salesforce Data Cloud capabilities that matter in real implementations.
1. Data ingestion with Data Streams
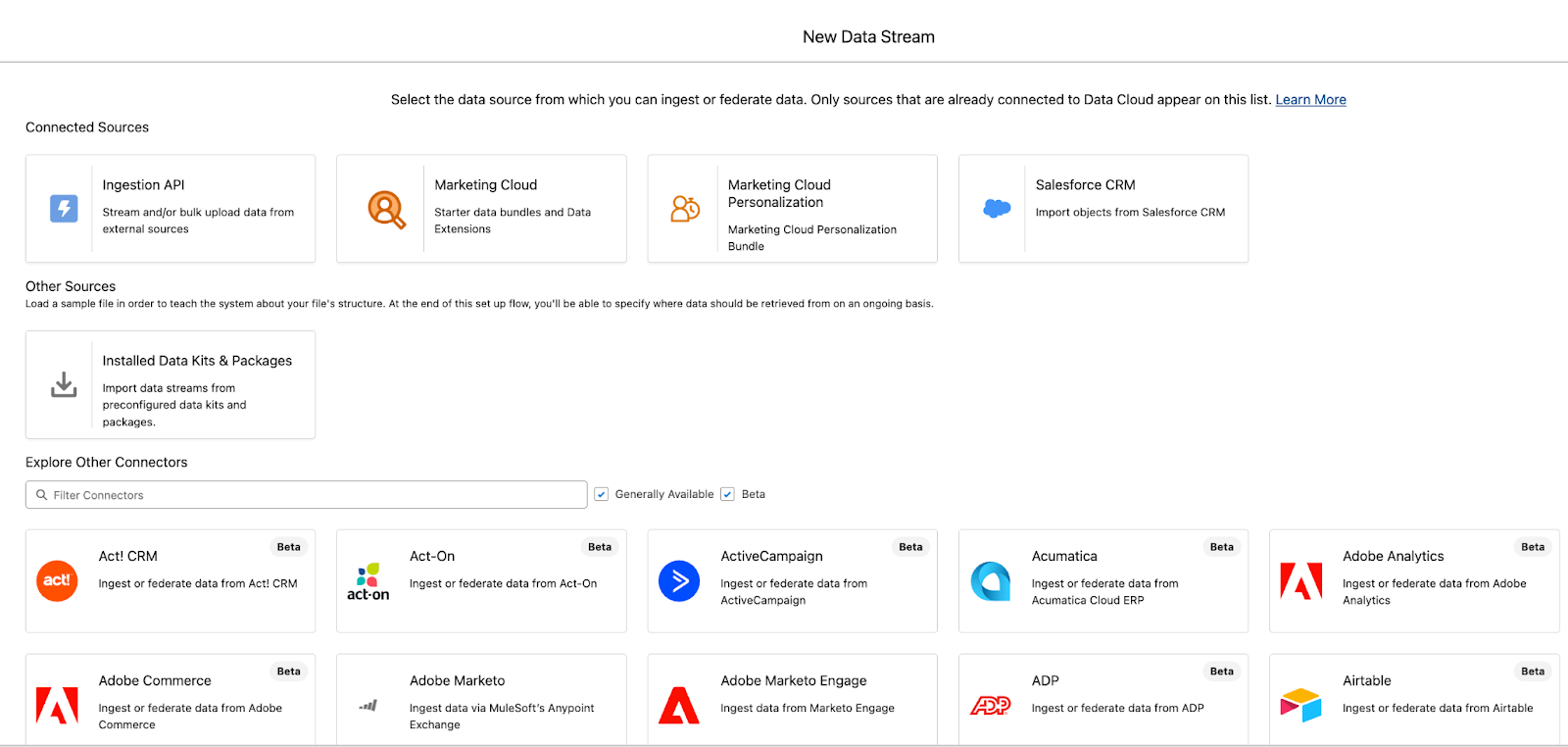
Every Data Cloud Salesforce implementation starts with Data Streams that bring data into the platform from CRM, e-commerce systems, mobile apps, websites, marketing platforms, and external sources.
These streams can operate in batch or near-real-time mode, depending on how frequently updates occur and how fresh the data needs to be.
Connections can be established in multiple ways:
- Native Salesforce connectors for CRM, Marketing Cloud, Commerce Cloud, and Service Cloud.
- API-based integrations for mobile apps, web platforms, and third-party tools.
- Data warehouse or data lake connections through Snowflake, AWS, or other storage systems.
- Even offline sources, such as loyalty programs or POS terminals, can be ingested through scheduled loads.
When a Data Stream is created, Data 360 detects the structure of the incoming dataset with fields, attributes, and relationships, and stores the data in Data Lake Objects (DLOs) in its original form.
These streams act as continuous pipelines that keep customer data flowing into Data 360 from every source, ensuring downstream processes always operate on fresh and relevant information.
2. Data Lake Objects (DLO) vs Data Model Objects (DMO)
Once data from different systems enters Salesforce Data 360, it needs structure to become consistent across all sources, since it comes in different field names and formats.
Data Lake Objects (DLOs) are the first stop. They store incoming data in the original format from each source. Field names, data types, and structures stay unchanged. DLOs are basically a safe holding area that preserves the original data without assumptions or transformation.
Data Model Objects (DMOs) serve a different purpose. DMOs define how customer data should look once it is ready to be used across systems. Teams map fields from DLOs into DMOs to align identifiers, attributes, and relationships. Email addresses, phone numbers, and transaction data end up following one shared structure, even if they came from very different sources.
Both layers are essential. DLOs protect raw data and source integrity. DMOs provide consistency and meaning. Together, they make it possible to build reliable profiles, apply identity rules, and support segmentation, activation, and analytics with confidence.
3. Identity resolution
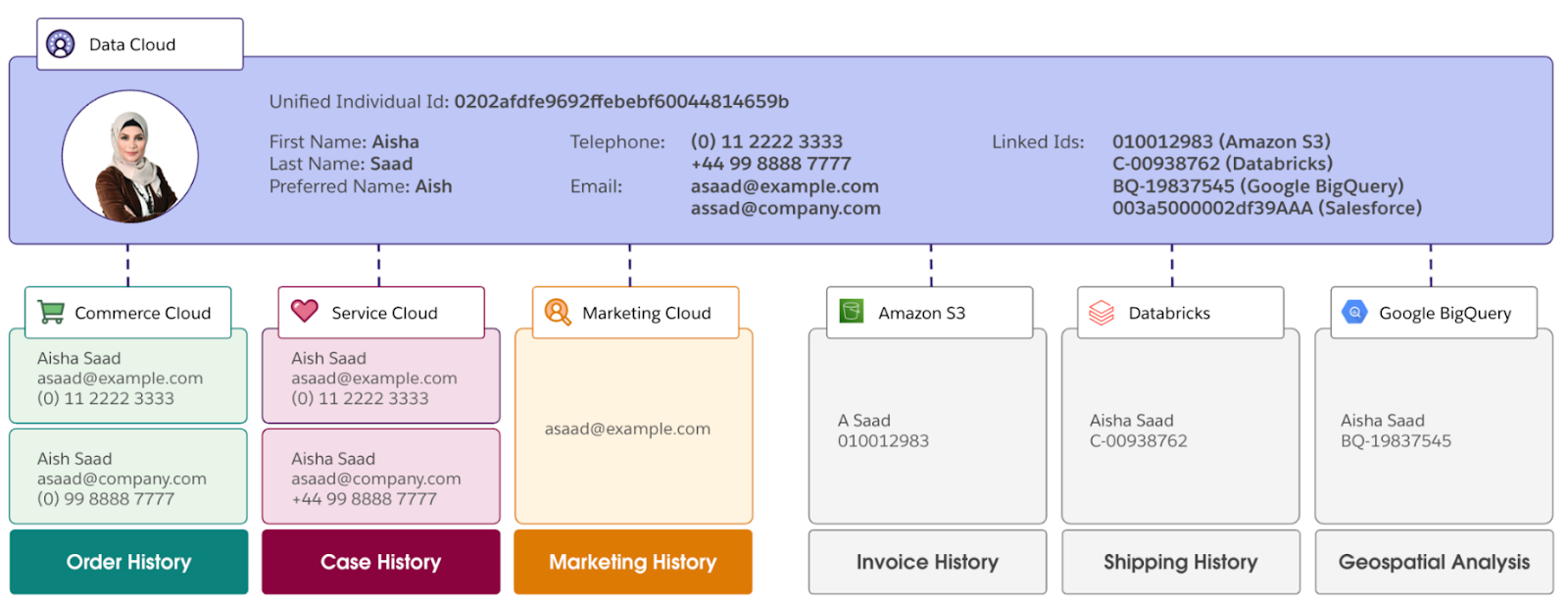
As data becomes standardized, Salesforce Data 360 can begin connecting the dots between records. Identity resolution is the process that links customer data across systems and channels to form a unified profile.
Data Cloud Salesforce uses two types of matching:
- Deterministic matching uses exact identifiers such as email, phone number, or customer ID.
- Probabilistic matching looks at indirect signals like behavior patterns, device information, or address similarities when exact matches are not available.
These rules work together. When multiple records point to the same individual, Data 360 links them and keeps the profile updated as new data arrives. Matching logic can be adjusted over time as data quality improves or new identifiers become available.
Identity resolution creates a reliable customer profile that supports analytics, personalization, segmentation, activation, and AI use cases. Instead of working with disconnected records and partial context, teams operate on a consistent view of the customer across all connected systems.
4. Calculated insights
Raw data on its own rarely helps teams make decisions. It needs to be shaped into metrics that reflect customer behavior over time. Calculated Insights do exactly that by turning events and transactions into values teams can actually use. Examples include engagement level, purchase frequency, lifetime value, or signals that indicate churn risk.
These metrics refresh automatically as new data arrives, ensuring insights remain accurate and timely. Instead of relying on static reports, teams work with continuously evolving indicators.
Because Calculated Insights are always current, teams can rely on them for segmentation and personalization without rebuilding reports or exporting data. The same metrics also feed AI models and automated logic, which keep decisions consistent across marketing, service, commerce, and analytics.
Calculated Insights sit at the point where data becomes usable. They connect raw inputs to real actions and help ensure decisions are based on shared, up-to-date signals rather than isolated reports.
5. Segments and activation
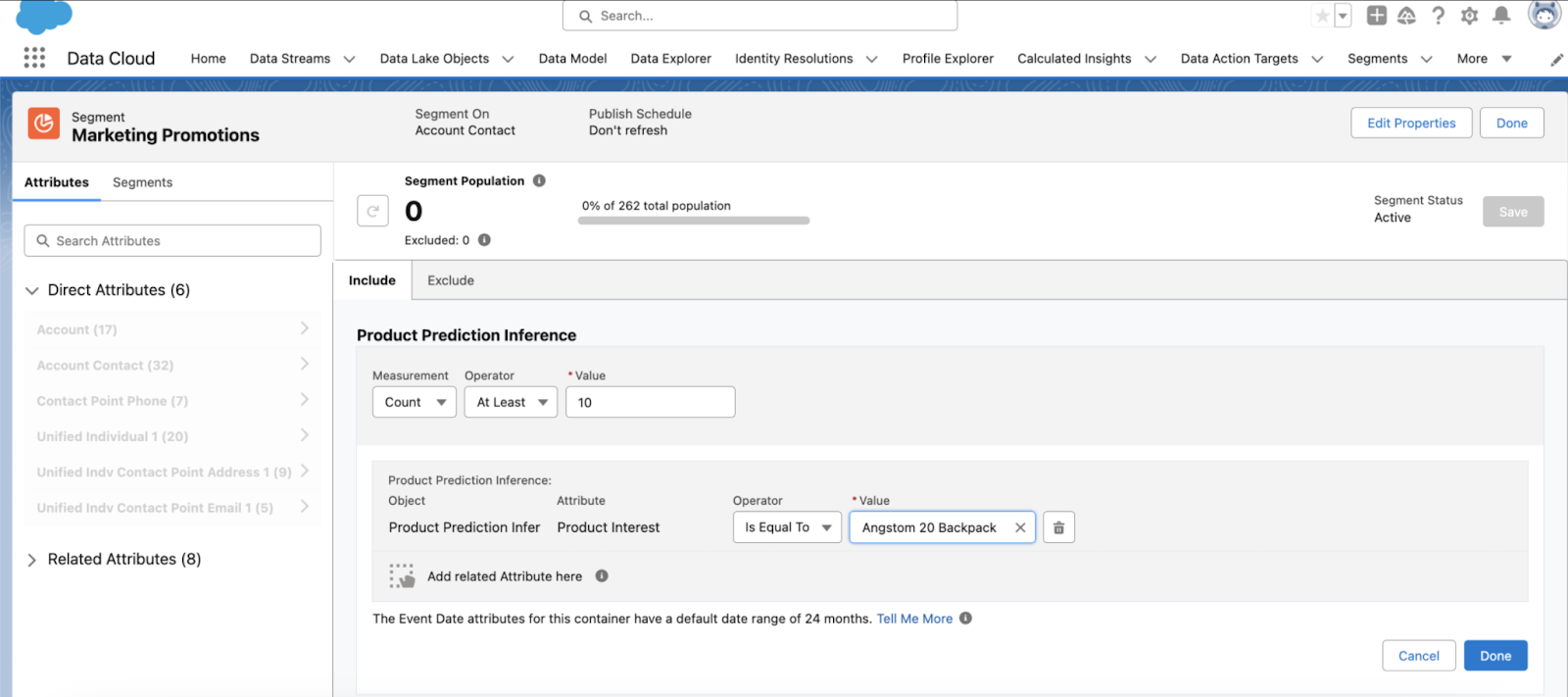
After profiles are unified and insights are in place, segments define how customer data is used. Segments group people based on attributes, behavior, or predictive signals, depending on the business goal.
Refresh timing is configurable. Some segments update on a schedule, while others evaluate changes close to real time. Teams can choose the right balance between speed, cost, and system load for each use case.
Activation moves those segments into action. Audiences can be sent to Marketing Cloud for journeys, surfaced in Service Cloud for context-aware workflows, used in Commerce Cloud for personalization, or shared with external platforms through integrations.
At this point, Data 360 shifts from analysis to execution. Insights now directly influence how systems respond to customer behavior across channels.
6. AI & Intelligence Layer (Einstein + Data 360)
At the top of the Data 360 stack sits the AI and intelligence layer, powered by Salesforce Einstein. Unified and trusted customer data gives AI models a reliable foundation, which improves the quality and relevance of predictions.
Customer profiles in Data 360 update continuously as new events arrive. Predictions adjust in step with real behavior, so scoring, prioritization, and recommendations stay current instead of relying on historical snapshots.
Within the Data 360 architecture, AI is built into the flow of data. Models consume unified profiles and calculated insights directly, supporting decision making across marketing, service, commerce, and analytics without separate data pipelines or delayed processing.
Salesforce Data Cloud integrations across the Salesforce ecosystem
Data 360 shows its full value when it is connected to the wider Salesforce platform. Unified profiles, live events, and frequently refreshed segments add shared context across clouds and replace fragmented views of the customer. Marketing, service, and commerce teams all work from the same source of truth.
Below are the integration patterns that deliver the most impact.
1. Marketing Cloud
Marketing Cloud benefits immediately from Data 360 because audience data stays current and consistent. Instead of static lists built on partial data, teams work with audiences based on unified profiles.
Typical use cases include:
- Segments from Data 360 are sent directly into Marketing Cloud for journeys, campaigns, and personalization.
- Events such as abandoned carts, product views, app activity, or service interactions can trigger journeys in real time.
- Attributes like lifetime value, engagement score, and purchase history help personalize content across email, mobile, and other channels.
- Profile updates flow from Data 360 into Marketing Cloud audiences, reducing duplication and data mismatches.
- Higher relevance and stronger engagement follow because campaigns respond to current behavior rather than delayed snapshots.
2. Service Cloud
Service teams often work with limited context. A case record shows what happened before, but not what the customer is doing right now. Data 360 changes that by extending Service Cloud with live behavioral, transactional, and predictive data.
Key integration patterns:
- Inside the Service Console, agents can see a unified customer profile with context that includes recent purchases, digital activity, lifecycle attributes, and segment membership.
- Calculated Insights add another layer. Signals such as declining engagement or increased service risk help agents spot problems early and adjust how they respond. Instead of treating every case the same way, support becomes situational and informed.
- Recommendations reflect the customer’s current state and history, whether that means suggesting a troubleshooting step, flagging a retention risk, or guiding the next interaction.
- Case routing can use Data 360 attributes like value tiers, recent behavior, or risk scores to prioritize customers more accurately.
- In more advanced setups, these same Data 360 attributes can also power AI-driven workflows and service agents that automatically recommend or initiate next steps.
3. Commerce Cloud
Commerce Cloud (Agentforce Commerce) becomes significantly more intelligent when powered by Data 360. Every product view, cart update, and purchase feeds into the same unified customer profile, so commerce activity no longer lives in isolation.
Core integration benefits:
- Personalization improves because recommendations can rely on a full history, not just recent sessions. Affinities, purchase frequency, and propensity scores help shape product suggestions that reflect real customer intent.
- Cart events and browsing activity flow into Data 360 as they happen and can trigger journeys, messages, or offers shortly after. Commerce activity influences marketing and service at the same time, rather than hours later.
- Commerce data stays visible across clouds. Marketing communications reflect what customers actually viewed or bought, and service teams see recent commerce events when handling cases.
- Customers get relevant offers at the right moment, improving conversion rates and average order value.
4. CRM Analytics (Tableau)
Analytics teams often spend more time preparing data than analyzing it. Reports rely on exports, stitched datasets, and manual fixes that break as soon as data changes. Data 360 removes much of that friction by providing a harmonized dataset that feeds both Tableau and CRM Analytics.
Integration use cases:
- Customer data from marketing, commerce, and service follows the same structure and identity rules. Deduplication happens before reporting starts, not inside dashboards.
- Metrics such as engagement, lifetime value, or churn indicators are defined once in Data 360 and reused consistently across reports.
- More reliable trend and cohort analysis powered by unified profiles and calculated insights.
5. MuleSoft, APIs, and external platforms
Data 360 isn’t limited to Salesforce products. Through MuleSoft, APIs, and activation connectors, it becomes the central audience and data layer for your entire ecosystem.
Key examples:
- Advertising platforms are a common example. Segments built in Data 360 can be activated in channels like Google Ads, Meta, or TikTok, keeping targeting aligned with the same profiles used in marketing and service.
- Core platforms such as ERP, loyalty systems, or custom applications can send data into Data 360 via MuleSoft or consume unified profiles and segments from it.
- Offline signals, including in-store purchases or call center interactions, can also be added to complete the customer view.
- Unified profiles and audiences can be shared with downstream systems for analytics, personalization, or automation wherever customer decisions are made.
Salesforce Data Cloud implementation strategy and steps: from business outcomes to production go-live
Implementing Salesforce Data 360 is a structured, multi-stage program spanning data architecture, identity resolution, governance, and activation. Treating it as a simple “data ingestion project” often leads to rework, scalability issues, and delayed value. The following stages outline a practical, engineering-driven path from initial setup to production go-live.
One of the most common mistakes in Data 360 implementations is starting with data ingestion instead of outcomes. While it’s tempting to connect every available source early, this approach often results in unnecessary complexity, higher costs, and unclear business value.
Instead, the implementation begins by defining a limited set of business-driven use cases that explicitly depend on Data 360. These typically fall into three categories:
- real-time marketing activation;
- service context enrichment;
- AI-driven insights and scoring.
Each use case is tied to explicit success metrics, such as time-to-segment, identity match rate, activation latency, or service efficiency, and allows to measure the progress objectively.
Only after outcomes are clearly defined are dependencies mapped backward:
- Which processes require unified profiles?
- Which insights must exist before activation?
- Which data sources are actually required for the first stage?
This approach keeps the initial scope intentionally narrow. Historical data, secondary systems, and edge-case attributes are usually deferred until core data flows are stable and trusted. As a result, Data 360 delivers visible value early instead of becoming a long-running data harmonization exercise.
Stage 1: Platform foundation, governance and data space strategy
With use cases and success metrics defined, the first technical stage establishes a stable and governed foundation for Salesforce Data 360.
Key activities include:
- Enabling Data 360 in the target Salesforce org and validating Data 360 entitlements, including product-level access, available credits, and confirming that the required Data 360 components are enabled and their visibility configured in the target org.
- Defining environment strategy (sandbox vs production, deployment sequencing).
- Establishing governance standards:
- data classification and PII handling
- naming conventions for Data Streams, DMOs, and Calculated Insights
- ownership and change management responsibilities
- Defining a high-level Data Space Strategy, including logical data separation (for example, by business unit, region, or use case) and access boundaries, as these decisions directly influence identity resolution scope and activation behavior, and must be established before ingestion and modeling begin.
The outcome of this stage is architectural clarity and operational readiness, but not yet data completeness.
Stage 2: Canonical data modeling aligned to use cases
With the platform foundation in place, the next stage focuses on defining a canonical data model that supports the agreed business outcomes before any large-scale ingestion begins.
The purpose of this stage is not to model all available enterprise data, but to define a minimal, stable data model that enables the initial use cases with clear semantics and predictable behavior.
Key activities include:
- Identifying authoritative source systems for each data domain (for example, profile data, consent, transactional data, behavioral events).
- Defining which data belongs to:
- profile-level entities used for identity resolution and segmentation,
- event or fact-style entities used for behavioral analysis and insights.
- Mapping required attributes to standard and custom Data Model Objects (DMOs), favoring standard models where possible.
- Defining which attributes are:
- required for identity resolution,
- required for activation or segmentation,
- optional or deferred to later stages.
Special attention is given to identity-related attributes at this stage. Decisions around which identifiers are modeled, how they are normalized, and where they reside in the data model directly affect downstream identity resolution and must be made intentionally.
The output of this stage is a logical canonical model independent of specific source mappings, that clearly defines:
- which DMOs exist,
- what each DMO represents semantically,
- which attributes are in scope for the first implementation.
The model serves as the architectural contract for the next stage, where physical data ingestion and Data Stream mapping are implemented.
Stage 3: Targeted data ingestion, data streams, and credit-aware design
Data ingestion is implemented only for sources required by the initial scope.
Implementation focuses on:
- Configuring Data Streams for selected systems.
- Mapping source fields to the predefined DMOs.
- Selecting appropriate refresh modes and ingestion schedules based on source characteristics.
- Validating ingestion behavior using small, representative data volumes before scaling.
At this stage, credit consumption is treated as a design constraint, not an optimization exercise. Decisions such as:
- ingestion frequency,
- streaming versus batch ingestion,
- initial historical depth,
are made with awareness of their impact on credit usage, while prioritizing functional correctness and use-case enablement.
Ingestion success in this phase is measured by correctness and reliability, not raw throughput.
Stage 4: Identity resolution strategy and profile unification
Identity resolution is configured strictly to support the initial activation scenarios.
Key considerations:
- Selecting deterministic identity rules aligned with available identifiers.
- Defining match priorities and merge behavior.
- Separating known and anonymous identity flows where applicable.
- Validating unified profiles against known test cases and edge scenarios relevant to the use cases.
Identity rules are intentionally conservative early on and expanded only after data quality and match behavior are well understood.
Stage 5: Data harmonization and calculated insights
Once unified profiles are stable, raw data is transformed into activation-ready signals.
This stage includes:
- Normalizing key attributes (timestamps, currencies, statuses).
- Aligning semantics across sources for consistent interpretation.
- Defining Calculated Insights that directly support segmentation, scoring, or AI-driven use cases.
- Validating calculation windows, refresh frequency, and performance characteristics.
Calculated Insights are treated as versioned, production-grade assets rather than ad-hoc aggregations.
Stage 6: Segmentation and activation validation
Before go-live, downstream consumption is validated end-to-end.
Activities include:
- Building segments that directly map to business scenarios.
- Verifying segment accuracy against expected profile counts and attributes.
- Testing activation paths to target systems (Sales, Service, Marketing, or external consumers).
- Measuring activation latency and operational impact relative to the defined success metrics.
This stage ensures that Data 360 outputs are actionable, not merely technically correct.
Stage 7: Testing, monitoring, credit consumption, and operational readiness
A formal readiness stage ensures the platform can be supported in production.
Focus areas include:
- Validation of ingestion health and error handling.
- Identity resolution stability under realistic data volumes.
- Monitoring data processing behavior and operational performance.
- Establishing visibility into credit consumption patterns under expected production workloads.
- Validating access control and data visibility.
- Defining alerting expectations, operational dashboards, and support runbooks.
At this stage, credit usage is evaluated as part of production readiness to ensure the solution operates within agreed limits and scales predictably as data volumes grow.
Stage 8: Controlled go-live and incremental expansion
Go-live is executed as a controlled rollout aligned to the original use cases.
Post-launch activities include:
- Monitoring ingestion, identity resolution, activation behavior, and credit usage.
- Refining rules and Calculated Insights based on real production data.
- Incrementally onboarding additional data sources and use cases.
- Expanding historical depth and secondary attributes only after core flows are proven stable and trusted.
This staged expansion ensures Data 360 scales sustainably while continuing to deliver measurable business value.
Common pitfalls of Salesforce Data Cloud implementation and how to avoid them
Even with a well-designed architecture and a clear plan, Salesforce Data Cloud implementations can fall short if key risks are ignored. The issues below come up often in real projects and usually lead to delays, rework, or higher costs.
1. Ingesting data before defining how it will be used
One of the most damaging mistakes is treating Data 360 as a place to “load everything first and decide later.” While this mindset is common in traditional data lakes, it works poorly in Data 360.
Once data is ingested, it is modeled into specific categories (profile, engagement, or other), and those modeling decisions are effectively fixed. If data is later discovered to be incorrectly modeled or misaligned with intended usage, the only option is to redesign and re-ingest, doubling effort and cost.
How to avoid it:
- Define business use cases and activation scenarios before creating Data Streams.
- Be explicit about how each dataset will be used downstream (segmentation, activation, analytics, AI).
- Document modeling intent before ingestion to avoid rework later.
2. Lack of data governance and hygiene
Without governance, Data 360 environments quickly become inconsistent: duplicate fields, unclear transformations, and conflicting definitions of the same attribute.
This is compounded by poor data hygiene. Placeholder emails, test records, or unstandardized formats immediately undermine trust in unified profiles and analytics.
How to avoid it:
- Establish naming conventions, data ownership, and documentation early.
- Maintain a shared understanding of canonical attributes across sources.
- Clean or filter test, junk, and low-quality records before ingestion.
- Standardize formats (dates, phone numbers, enums) consistently.
3. Overloading Data 360 with unnecessary data
Another common mistake is ingesting all available fields “just in case,” with the intent to clean or filter later.
This approach significantly increases processing load, storage footprint, and credit consumption, often without adding any business value.
How to avoid it:
- Ingest only attributes required for defined use cases.
- Limit transformations to what is strictly necessary.
- Filter irrelevant or unusable records upstream whenever possible.
- Treat every field as a cost decision, not a free addition.
Lean ingestion designs scale better and are easier to maintain.
4. Ignoring data governance, consent, and privacy requirements
Data 360 often consolidates sensitive customer data from multiple systems. Ignoring consent, privacy, or regulatory requirements creates serious compliance and reputational risks.
Retrofitting governance controls after activation has started is difficult and error-prone.
How to avoid it:
- Define data classification and PII handling rules before ingestion.
- Align Data 360 design with existing consent and privacy frameworks.
- Ensure access controls and data visibility reflect regional and regulatory constraints.
- Regularly audit what data is activated and where it is sent.
Governance directly determines what data can be used, and what must not.
5. Underestimating data credit consumption
Data 360 operates on a credit-based consumption model. Ingestion, processing, segmentation, and activation all consume credits, and costs can escalate quickly if this is not considered during design.
How to avoid it:
- Monitor usage through Digital Wallet and Data Cloud credit dashboards.
- Design ingestion cadence, segmentation refresh rates, and historical depth intentionally.
- Test ingestion, identity rules, and segments with limited datasets before scaling.
- Validate credit impact in sandboxes or controlled environments before production rollout.
- Apply data retention and scoping strategies aligned with real business needs.
Credit consumption should be treated as an architectural constraint, not an afterthought.
Noltic’s Salesforce Data Cloud implementation services
Large Salesforce Data Cloud programs fail for clear reasons: unclear use cases, weak identity design, missing governance, and activation that never reaches real teams. Noltic, as a trusted Salesforce Data Cloud partner, helps organizations avoid these issues with an outcome-driven and production-focused approach.
Why clients choose our company:
- 150+ Salesforce projects completed;
- 95 certified Salesforce experts, including 8 Salesforce Architects;
- 400+ Salesforce certifications;
- 5.0 AppExchange rating based on 96 verified reviews;
- 5.0 Clutch rating;
- Salesforce Data Cloud Level 1 specialist expertise with specific Salesforce Data Cloud certifications.
What Noltic delivers during Salesforce Data Cloud implementation:
1) Use case and value definition:
- Clear Data Cloud use cases tied to business outcomes;
- Measurable success criteria such as identity match rate, segment refresh time, and activation latency;
- Controlled scope to avoid early over-ingestion and credit waste.
2) Data Cloud architecture and modeling:
- Canonical data model aligned to Salesforce standards;
- Clear separation of profile data, event data, and calculated metrics;
- Design choices that support identity resolution and activation from day one.
3) Data ingestion and integrations:
- Data Streams for Salesforce and external systems;
- API and MuleSoft integrations where needed;
- Credit-aware ingestion design to control cost and scale safely.
4) Identity resolution and profile unification:
- Deterministic and probabilistic matching strategies;
- Known and anonymous identity handling;
- Validation with real customer scenarios, not synthetic samples.
5) Calculated Insights, segmentation, and activation:
- Business-ready Calculated Insights reused across teams;
- Segments built for real marketing, service, and commerce workflows;
- Activation into Salesforce clouds and external platforms.
6) Governance, privacy, and operating model:
- PII handling and access rules defined early;
- Alignment with consent and regional requirements;
- Clear ownership model for long-term maintenance.
7) Post go-live support:
- Iterative improvements based on real usage;
- Expansion to new sources and use cases without rework;
- Ongoing advisory and managed support for Data Cloud.
When teams bring us in:
- Data Cloud is licensed, but identity and activation are unclear;
- Segments refresh slowly or cost more than expected;
- Marketing, service, and analytics teams see different customer data;
- AI use cases are planned, but data trust is missing.
Conclusion
Salesforce Data 360 goes beyond data unification. It acts as an operational layer that supports real-time decisions across marketing, service, commerce, analytics, and AI. Results depend less on the volume of data ingested and more on intent, structure, and activation.
Teams that start with clear outcomes, apply disciplined data modeling, and roll out Data 360 in phases reach value faster and avoid rework. A credit-aware approach keeps costs predictable and supports long-term scale.
When implemented with purpose, Data 360 connects more than systems. It aligns teams around a shared customer view and supports consistent decisions based on current, trusted data.
.png)

together